tags:
- OS
- IO Systems
第一课 I/O Devices
在第一个阶段时,我们提到了计算机的五大部件,包括输入设备、输出设备、存储器、运算器和控制器。站在上层封装好的视角,计算机主要做了三件事:输入-运算-输出。运算是CPU为我们完成的,对于我们用户而言,一台计算机I/O就基本上决定了机器的可使用性(想想,一台只有机箱的电脑。尽管安装了操作系统,你仍无法操作这台机器)。
相比CPU那几个固定的架构,IO的处理可就麻烦多了(鼠标、硬盘、打印机、键盘、音响、摄像头......)。即使不同I/O设备可能遵循行业内的相关协议,而且我们现在有各式各样的USB I/O设备为I/O的管理提供了便利。但由于这些设备使用的数据、工作方式的不尽相同,处理这么多不同种类的I/O是一件令操作系统头大的事。
1.1 Bus, Ports, Drivers and So...
I/O设备能够工作离不开总线(bus) 和控制器(controller) 的支持。前者负责I/O设备与主机(host)的连接,后者负责信号转换、数据缓冲和设备控制。I/O设备往往由唯一的I/O端口(控制器)所标识,I/O端口通常包含四个寄存器:输入数据寄存器(input data register)、输出数据寄存器(output data register)、状态寄存器(status register) 和控制寄存器(control register),有些设备还包括地址寄存器(address register)。
1.1.1 Bus
总线是一组线路和通过这些线路传输信息的协议。在计算机系统中,总线用于连接计算机的各个部件,是他们能够互相通信。总线承担着数据、地址和控制信号传输的功能,是计算机系统中不可或缺的一部分。总线可以根据传输方式分为并行总线和串行总线。
1.1.1.1 Parallel Bus
并行总线会使用多条线路同时传输多位数据。每条线路传输一位bit,多条线路可以同时传输多个bits的数据。但是并行总线之间存在电磁干扰,会导致信号的完整性和同步性问题。虽然直觉上并行总线肯定是要比串行总线快的,但当传输频率变高时,严重的信号干扰和同步问题又会使得并行总线的传输效率下降。常见的并行总线有IDE(Integrated Drive Electrons)、PCI(Peripheral Component Interconnect) 等。
1.1.1.2 Serial Bus
串行总线虽然只使用单条线路传输一位数据,但由于其信号的干扰更少,所有串行总线可以在较高的时钟频率下运行,从而实现了高效的数据传输。且串行总线的成本更低,支持更长距离的传输。现代高速传输技术,如USB(Universal Serial Bus)、SATA(Serial ATA) 和PCIe(PCI Express),都是基于串行传输的。
1.1.2 Ports
端口是一个很有趣的话题。我们可以把端口的类型分成物理端口和逻辑端口。物理端口是人类可以直观看到、摸到的,包括总线和控制器。而逻辑端口则是操作系统视角下的I/O端口。我们接下来介绍物理端口和逻辑端口。
1.1.2.1 Physical Ports
物理端口可以理解为计算机与I/O设备连接的接口。通过端口,计算机系统可以与各种外设进行数据交换。端口的种类繁多,每种端口都对应着不同总线协议的功能实现和特定的连接标准。常见的端口有USB、HDMI等。
1.1.2.2 Logical Ports(Application I/O Interfaces)
逻辑端口提供了一种抽象,使得应用程序不需要了解底层硬件的具体细节。通过逻辑端口,应用可以通过统一的接口与各种I/O设备进行交互。现代操作系统支持即插即用技术,使得用户可以方便地添加和移除I/O设备。操作系统会自动检测新设备,并加载相应的驱动程序,使设备能够立即使用。操作系统的I/O子系统提供了这样一套标准化的逻辑端口。
在早期的操作系统中,操作系统仅支持几个特定的I/O设备。你要使用某个设备,你就需要更新或者换成另外支持这个设备的操作系统。由于I/O设备的数量太过于庞杂,这种方式的管理太过于麻烦。IBM PC的一大成功就在于每个用户都可以通过一个标准的接口将自己的I/O设备加入到系统中。
1.1.3 Device Drivers
我们说逻辑接口是内核I/O子系统提供的逻辑接口。为了使这样的逻辑接口便于上层所有的应用提供服务,我们需要在操作系统和I/O设备之间增加一层抽象,即设备驱动程序,以便实现设备的操作和管理。为了逻辑接口的标准统一,I/O子系统向下提供了一个标准的驱动程序接口。因此,不同设备使用统一的驱动程序接口。
设备驱动程序是操作系统与硬件设备之间的桥梁。它们负责将操作系统的高级指令转换为设备控制器能够理解的低级指令,并将设备的反馈传递回操作系统。驱动程序的质量直接影响系统的稳定性和性能,因此高质量的驱动程序对于系统的正常运行至关重要。
1.1.3.1 Devices Abstraction
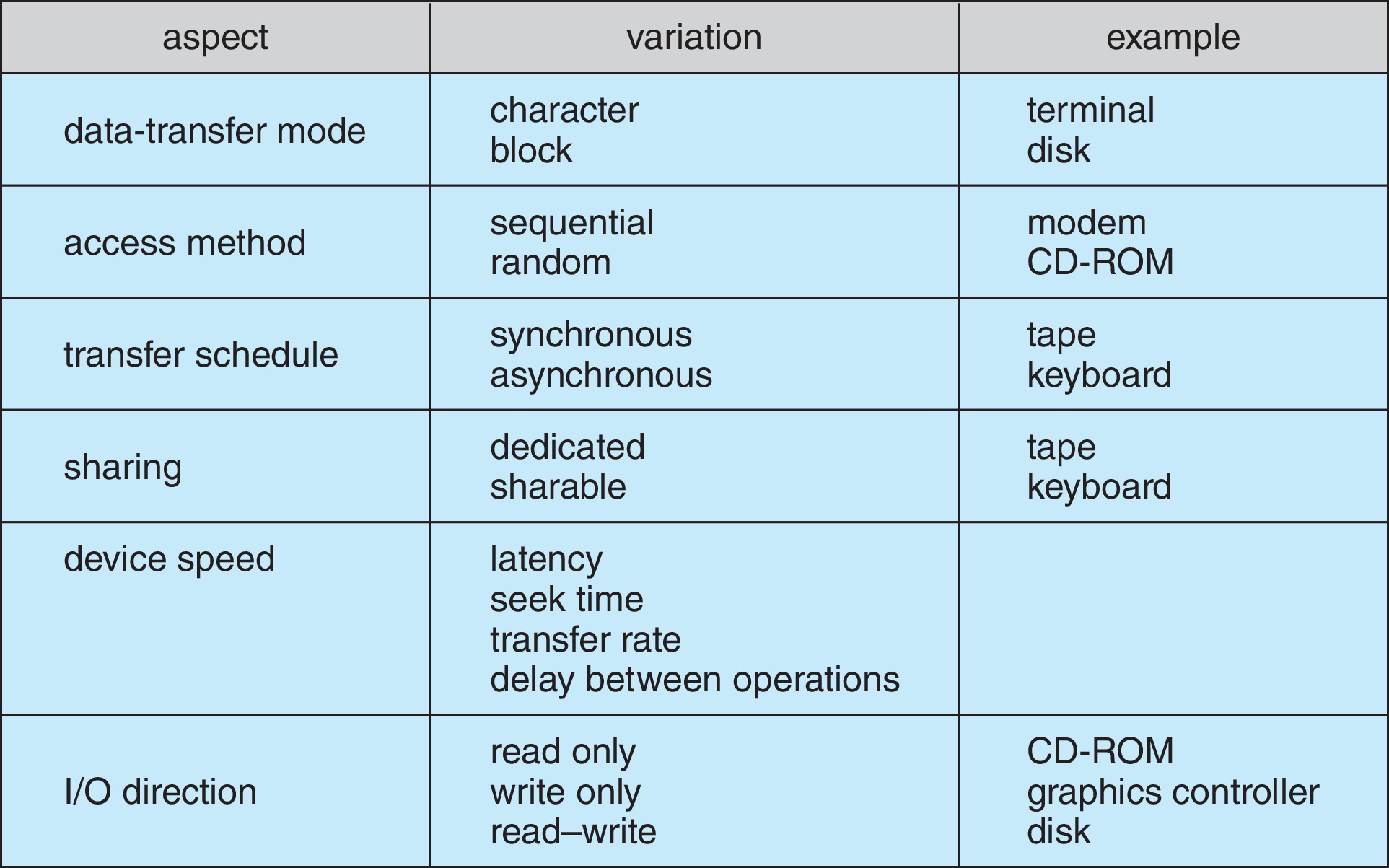
硬件设备各不相同,为了实现对设备更方便的管理,系统会从下面几方面来对设备进行抽象分类:
- Data transfer mode
- Access method
- Transfer schedule
- Dedication
- Device speed
- Transfer direction
1.1.3.x BSOD
在Windows系统设计中,设备驱动程序会在内核模式下运行,其他的一些操作系统可能会将驱动程序运行在用户模式或者用户-内核之间的模式下。
Windows中,设备驱动程序在内核下运行可以唤起引发蓝屏(blue screen of death)的系统调用。这是Windows常被人诟病的方面之一,尽管Windows很无辜(引发蓝屏并不是系统的问题),可能是某些I/O设备引发的问题。而通常情况下,用户并不能注意引发蓝屏问题的原因是什么。
为了解决BSOD的问题,Windows在系统中加入了许多设备的驱动程序作为其默认的驱动。如果系统中没有某个设备的驱动程序,厂商可以先在Windows上进行驱动器的测试,确保在Windows的环境下安装驱动后不会引发BSOD。通过测试的设备会获得Windows的认证标志,表示该设备在Windows系统中可以稳定运行。
1.1.4 Device Controller
如果说设备驱动器作为最底层的软件层实现了I/O设备的逻辑端口的话,设备控制器则更像是提供I/O设备的物理端口。I/O控制器是一种用于管理I/O设备和主机之间传输数据的硬件,用于管理和操作I/O设备。每种I/O设备都有特定的控制器,通常而言,I/O控制器会集成在主板上,也可以通过扩展卡的形式存在。
设备控制器直接接受来自主机传输来的指令信号,并负责将来自主机的指令转换为设备可以理解的电信号控制设备的运作。设备完成后,控制器还要负责将设备的响应反馈给主机。
1.1.5 Abstraction Layers
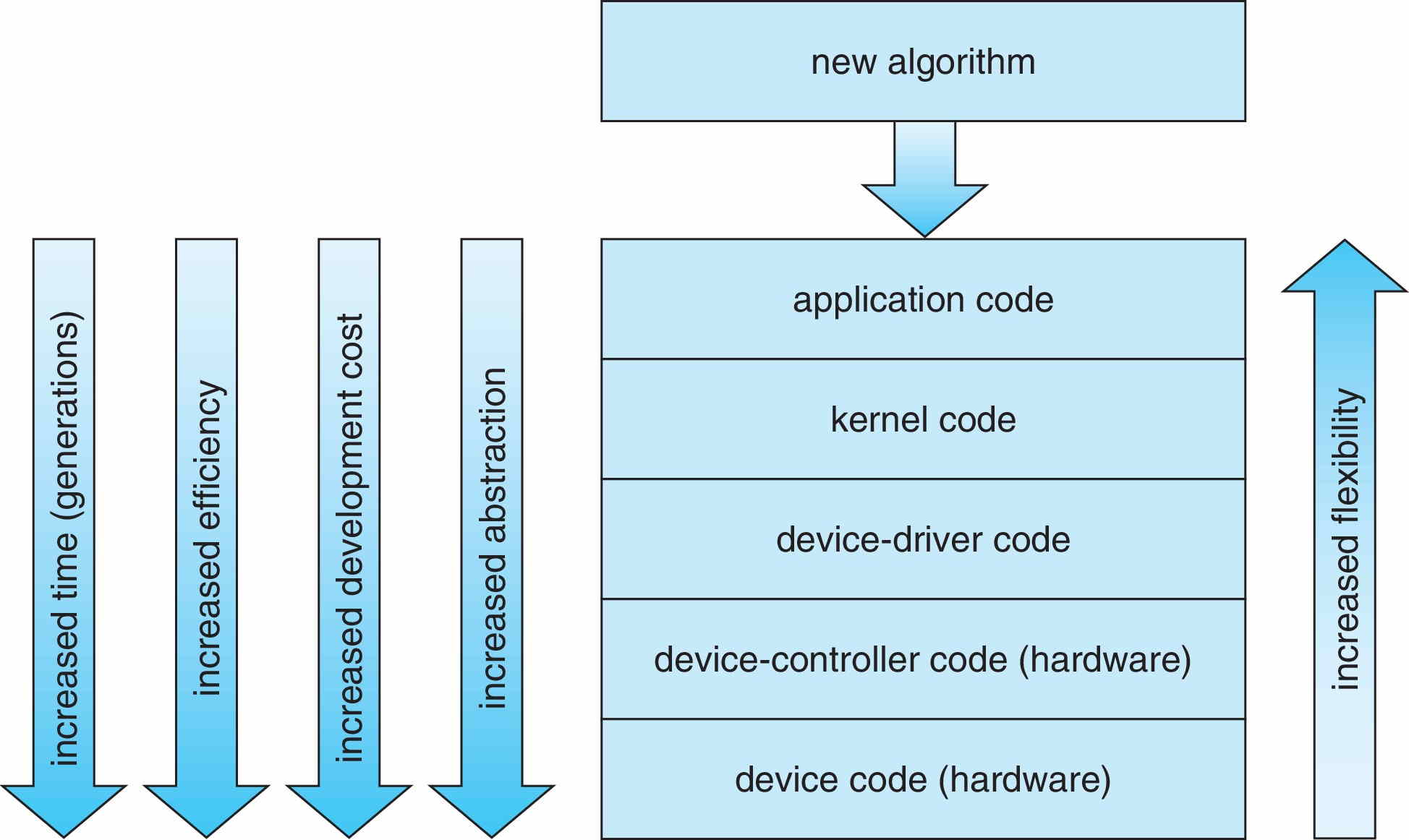
了解完了设备的驱动程序和控制器,我们现在知道,驱动程序是内核和控制器(硬件)之间的桥梁,而控制器是实际上控制设备工作的电子元件。即层次化的关系是 kernel -> drivers -> controller。那么用户想要使用某个设备,总共需要穿越多少个抽象层?
当我们想要使用一个设备时,我们需要将想法编写成应用程序。由于操作系统的封装性和保护性,我们需要使用系统调用来间接地使用I/O设备。内核的I/O子系统会根据高级指令寻找对应的设备驱动程序,由驱动程序将上层的指令转换成设备控制器能够理解的低级指令,并发送给设备控制器。最后,设备控制器解析这些低级指令来控制设备做出相应的动作。
1.1.6 Block and Character I/O Devices
根据数据的传输模式,我们可以将I/O设备分为块设备和字符设备。在使用相关的系统调用时,我们应当注意块设备每次应至少 read 或 write 一个块,而不是一个字节。字符设备也应每次 get 或 put 相应的一个字节。
1.1.6.1 Block I/O Devices
块设备是面向块设备(譬如磁盘)的设备。任何的设备都支持 read 和 write 指令,如果这个设备是一个随机访问的设备,那它还会有一个 seek 指令跳转到相应的块。应用程序通常上经由文件系统访问磁盘。
块设备的特点是它们可以以固定大小的块进行数据传输,这样可以提高数据传输的效率。块设备通常用于存储设备,如硬盘和光盘。
1.1.6.2 Character I/O Devices
字符设备是面向比特流(例如键盘)的设备。字符设备的相关系统调用有 get 和 put。字符设备通常用于需要逐字节处理数据的设备,如串口设备和终端设备。
字符设备的特点是它们以字符流的形式进行数据传输,这样可以更灵活地处理数据输入和输出。字符设备通常用于输入输出设备,如键盘和鼠标。
1.2 Memory Mapped I/O
之前我们说过,I/O设备往往由唯一的I/O端口(控制器)所标识。要使CPU和正确的I/O设备进行通讯,控制器为每个寄存器分配了唯一的编号,即端口号(port number),也称为I/O地址。每个外设都需要通过I/O地址于CPU进行通信,通过不同的I/O地址,CPU能够知道数据发送的地方。
1.2.1 PMIO
端口映射I/O(Port-Mapped I/O) 是我们要介绍的第一种I/O地址类型,这种类型下的I/O地址是独立的,与内存地址无关。在开发板上,我们通常会看到这种I/O地址类型。设备拥有自己独立的I/O地址,CPU会通过专用的指令和信号与设备进行通信。例如,通过IN指令、OUT指令,以及控制信号IOR(I/O Read)、IOW(I/O Write)等来进行操作。
在这种方式下,I/O的地址总线和控制总线和内存的地址总线分离。然而,IO的数据总线仍然使用系统的数据总线。
1.2.2 MMIO
内存映射IO(Memory-Mapped IO) 方式下的IO地址被映射到了系统内存地址空间中。CPU通过访问内存地址来访问设备。这样一来,访问I/O就可以通过标准的内存访问指令来访问了,例如,MEMR和MEMW指令。它的总线和内存也都是共用的。

1.3 Polling, Interrupts and DMA
在计算机组成中,我们学习过轮询、中断和DMA(direct memory access)的I/O控制方式。我们本小节简单了解一下这三种方式的工作原理。
1.3.1 Tight Polling
轮询是最简单的I/O控制方式,尽管它的实现很直接,但在性能方面可能并不总是最佳选择。然而,有时候,轮询可能是你唯一能选的I/O控制方式。在轮询方式中,CPU会周期性地询问I/O设备:“你有没有需要处理的事情?/你忙不忙?我有些事情想让你做”。这种周期性检查设备状态的方法,尽管简单,却非常耗费CPU资源。
我们上述的轮询一般指tight polling(紧轮询),与之相对的,loose polling会在每次检查条件之间加入一定的延迟,以减少 CPU 的占用。这种方法更节省资源,但响应速度较慢。
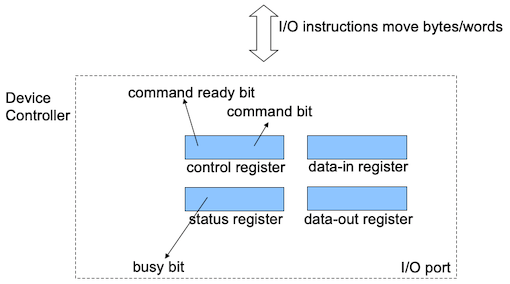
1.3.1.1 Busy Bit and Ready Bit
轮询会使用一个比特位来标识设备是否忙(busy bit),还有一个比特位标识设备的就绪状态(ready bit)。当设备忙时,busy bit就会被设置为1,标识设备正在执行某项任务。当设备就绪时,ready bit就会被设置为1,表示设备准备好接收新的数据了。
1.3.1.2 Polling Working Flow
CPU在对外设进行询问时,首先会检查设备是否忙碌,若是设备忙碌就不再打扰。当设备空闲时,CPU会给I/O端口特定的命令来读/写相应的数据。CPU会把ready bit设置为1,通知设备控制器可以执行新的命令了(如果是向外设输入数据,还需要向data-in register输入相关的数据)。
当设备控制器检测到相应就绪位的设置后,就会将busy bit设置为1,表示外设开始工作了。然后设备控制器从命令寄存器中读取命令并进行相应的操作。最后,设备控制器完成数据的处理后,会将ready bit和busy bit清除掉(置0),设备重新变为可用状态。
1.3.1.3 Something to be Considered
在Polling的情况下,由于要求CPU时时刻刻地参与,CPU的周期性轮询或忙等待某一个设备都会消耗CPU的资源,使得CPU利用率下降。Polling作为最简单的方法,可能并不是最优选。
而且如果CPU不及时响应,就可能造成数据的丢失。回到传感器的例子,由于传感器的缓冲区很小或是传感器对实时性的要求,如果不及时响应读取缓冲区内的数据,就可能导致新的数据覆盖掉旧的数据,导致数据的丢失。
1.3.2 Interrupts
在之前,我们用一个阶段来解释中断,但届时我们并没怎么涉及到什么关于I/O设备上面的中断。我们谈论到了外部中断,但只是一笔带过。那设备是如何向CPU发送相关的中断信号的呢?实际上,在物理线路的连接上,外设和CPU之间会架设一条中断请求线(Interrupt request line),外设通过向这条线路发送信号,CPU就能够识别到外设是否在请求中断。
CPU检测到中断之后,后面的流程和我们学过的就很类似了,保存上下文、调用中断处理程序和恢复执行。但是作为系列的末尾,我们有必要复杂化的看待问题,或者说它本来的样子。比如,我们需要考虑中断优先级、中断禁用(disabling interrupt) 等。
1.3.2.1 Watching Interruption by Example
在中断的方式中,CPU不需要时时刻刻地围绕在I/O身边,而是专注于做自己的事情。I/O设备一般都非常慢,当CPU少去大量忙等待的时间(第2、3步),效率自然就会提高。
在中断方式下,CPU需要做的是发送相关的I/O请求,之后不需要等待I/O设备的完成转而做其他事情。之后,I/O设备准备好之后向主机发送中断信号,CPU响应中断并执行响应的中断服务例程。之后恢复执行。
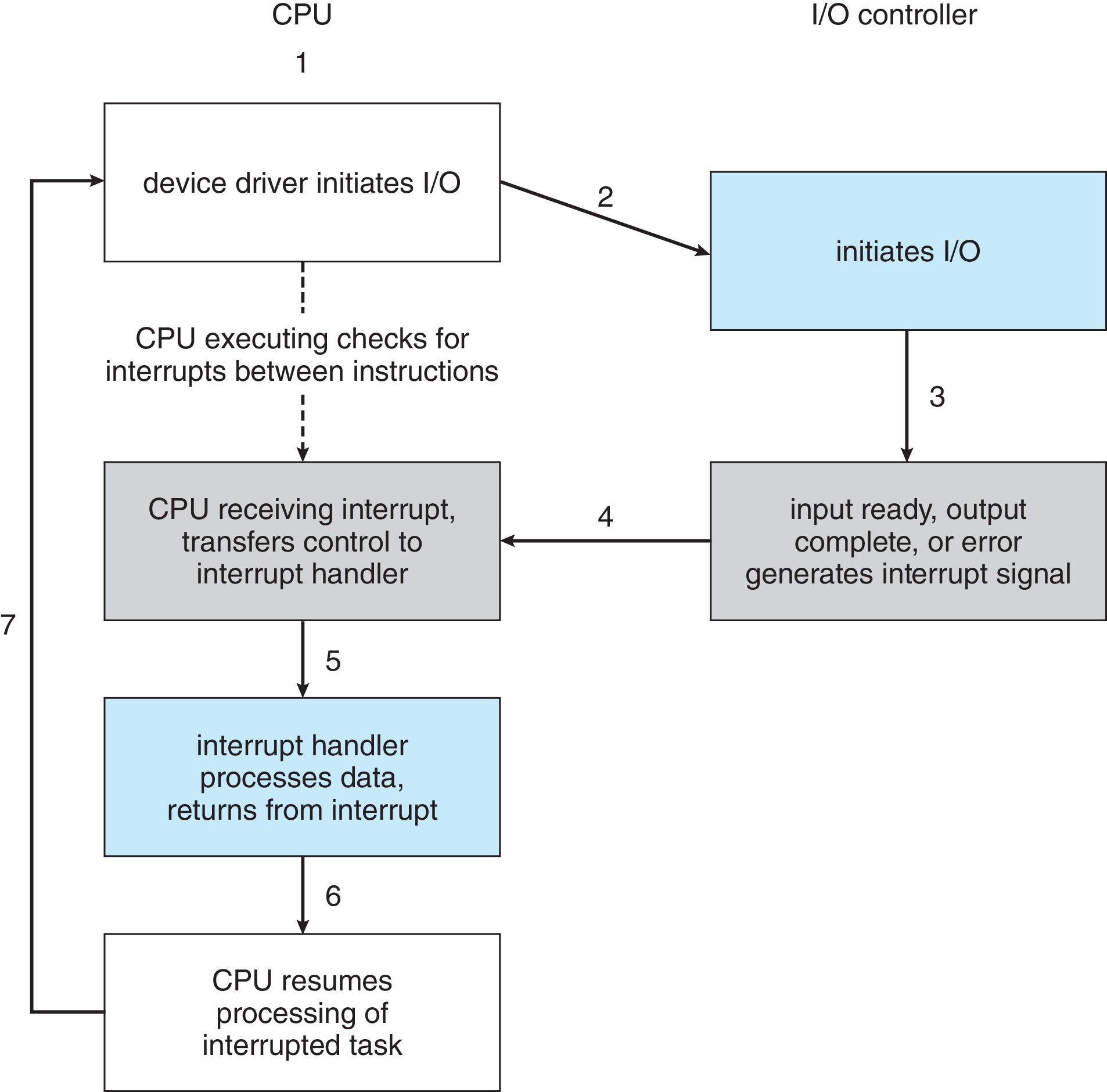
1.3.2.2 We Got a Better Choice
相比于轮询的I/O控制方式,中断总算是把CPU从繁重的periodic polling中解救出来了。在中断的I//O控制方式下,当设备需要CPU来处理时,设备可以发送中断信号给CPU,CPU只需要抽空过来处理就好了。但有时候,中断并不需要立即被相应执行。延迟处理(Delay handling)可能带来的效益更高,例如网络数据包的接收(NIC)。
相比轮询,中断的应用到处都是。而为了避免高频次的中断,延迟处理相关的I/O,我们下面开始介绍一种更好的I/O控制方式——DMA。
1.3.3 Direct Memory Access
没有DMA的世界中,当devices想向memory传输数据时,数据的流向必须经过CPU这个中介,即传输路径为Devices->CPU->Memory。而DMA的方式运行I/O设备直接对内存进行访问,绕过CPU进行数据传输。当传输完成之后,通知一下CPU就好(可能是一次中断)。
我们可以告诉DMA控制器(DMA controller)源是哪个I/O设备,目的在哪,读操作还是写操作。初始化DMA控制器完成之后,DMA控制器就可以代替CPU进行数据的传输任务,进一步解放了CPU。这种实现方式中,CPU仍然会被中断,但次数要少得多。实际上,DMA控制器并不完全独立于CPU,甚至可能会由于总线争用(bus contention)而拖慢CPU的运行速度。

1.4 ioctl
ioctl 是一个用于操作系统和设备驱动程序之间通信的UNIX系统调用。它允许应用程序通过设备文件向设备发送相关的控制命令。它的函数原型如下:
#include <sys/ioctl.h>
int ioctl(int fd, unsigned long request, ...);
/* Parameters:
1. fd: File descriptor of the device.
2. request: Device-specific request code.
3. ...: Additional arguments, depending on the request code.
Return value: Returns 0 on success, otherwise -1 and sets errno to indicate the error.
*/
这个系统调用的功能极为强大,这个部分有待更新。
第二课 Kernel I/O Subsystem
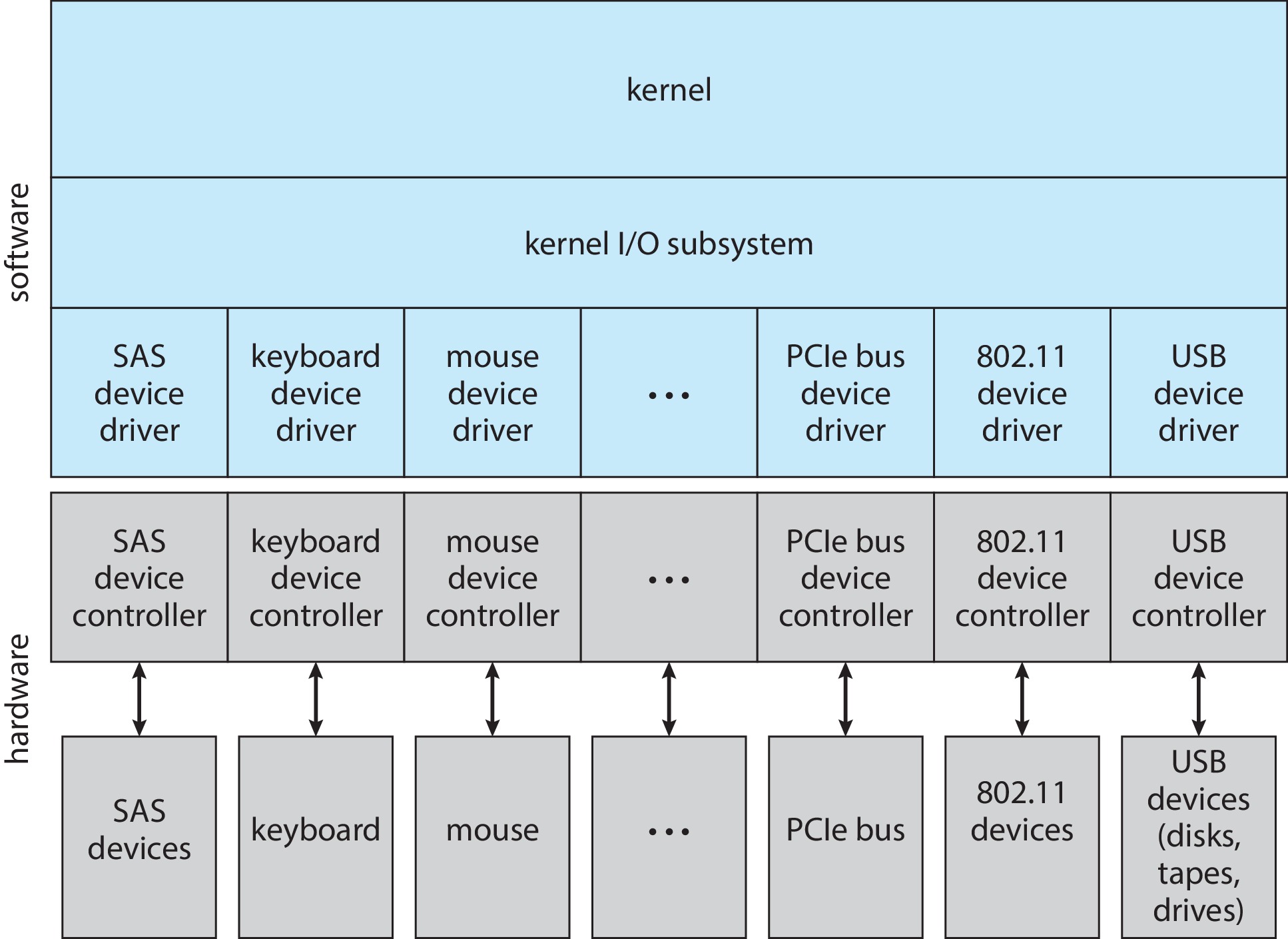
在第一节课中,我们见到过这张图,I/O系统结构是层次化的。而内核I/O子系统层位于设备驱动层之上,为上层的应用提供了虚拟的I/O端口,使应用程序可以通过统一的接口访问不同的硬件设备,而不必担心具体实现。为了提供更好的速度和安全性,这一层次还实现了buffering、I/O protection等。我们下面逐步了解这些内容。
2.1 Devices Independence
为上层应用提供统一的访问I/O设备的接口抽象是I/O子系统层的职责之一。无论是磁盘、打印机还是网络接口,应用程序都可以使用相同的系统调用与之进行交互。在类Unix的系统中,无论是字符设备还是块设备都被抽象成文件。一切对设备的访问都被看做是对文件的访问。
通过这种统一的文件模型抽象,我们可以使用相同的系统调用(比如,open()、read()等)对设备进行访问。这些设备文件被放在/dev目录下,这种将设备视为文件的抽象是文件系统在设备独立性上发挥的作用。
2.2 Buffering
不论是对于character-oriented devices还是block-oriented devices,由于设备之间传输速度不匹配的问题,我们在传输过程中需要增加一块缓冲区,这就是缓冲(buffering)的概念。比如,键盘是一个低速的外设,尽管你打字再快,在主机的视角来看仍然非常慢。如果你想用键盘在磁盘中的文件中写一些内容,每次都输入一个字符并同步一个块显然是不划算的。
Buffer相当于一个储水罐(reservoir),用于数据的暂存。当我们观看网络视频时,网络状况好的情况下,视频的播放一般会满慢网络中视频数据传输的速度。然而,如果网络状况时好时坏,我们就可以在网络好的时候将视频先暂存到buffer中,不至于在网络差的时候影响观看体验。
当高速设备给低速设备发送数据,若是没有buffering,低速设备没有办法准确的收到来自高速设备的数据。而低速设备给高速设备发送数据时,若是没有buffering,高速设备就会等待低速设备,这样会造成性能的浪费。

从操作系统的视角看,buffering的实现简单而直接:将一个东西加入到buffer和将一个东西从buffer中取出来。实际上就是生产者-消费者模型,我们之前也将其称为有限缓冲问题,还记得么?
2.2.1 Buffer Calculation
当我们引入了buffering,另一个问题就随之而来了。缓冲的大小应当设置多大,我们应当设置小缓冲区还是大缓冲区呢?当缓冲区很大时,一方面会挤占内存资源;另一方面,如果缓冲区过大,还会造成延迟的增加。当缓冲区过小,就会导致无法容纳足够的数据,这会导致频繁的I/O操作,还可能导致数据的丢失。
所以我们应当在一个范围内设置缓冲区的大小,从而在减少延迟和提升传输效率间找到平衡。假如 T 是向输入一个块所要的时间,C 是输入请求之间所需要的计算时间。那么,在没有buffer的情况下,完成将一个块的传输时间就需要:
2.2.2 Double Buffering
假设我们在码字。在只有一个缓冲的情况下,buffer满了,就会把buffer中的内容整个地写入到磁盘中。然而,写入磁盘并不是瞬间完成的,我们想要继续码字。在之前学习生产者-消费者问题时,我们就了解到,生产者和消费者,一时间只能有一个进入临界区。如果我们想要不间断地写,我们可能就需要两个buffer来存放我们生产的物品,这就是double buffering,即双缓冲。
在double buffering中,系统使用两个缓冲区(Buffer A 和 Buffer B)来存储数据。当一个缓冲区正在被填充数据时,另一个缓冲区可以同时被处理。这样,数据的读写操作可以并行进行,减少了等待时间。当一个缓冲区的数据处理完成后,系统会切换到另一个缓冲区继续操作。这个过程不断交替进行,从而实现高效的数据传输。
2.2.3 Circular Buffering
Circular buffering是双缓冲的进阶版,并不难想清楚。
2.4 SPOOLing and Device Reservation
SPOOLing(Simultaneous Peripheral Operations On-Line)是一种将数据暂时存储在中间存储设备(如磁盘或内存)中的技术,以便设备可以在后台处理这些数据,而不影响前台的操作。最典型的例子就是打印机。当向打印机发送多个打印任务时,这些任务会被暂时存储在一个缓冲区(spool)中。
当用户进程提交打印任务时,这个任务并不会直接送给打印机,而是送到一个提供SPOOLing service的服务器上,这个服务器会将提交的这些任务排序,最后逐个打印。这种方式可以提高系统的效率,因为计算机可以继续处理其他任务,而不需要等待打印机完成打印。
2.5 I/O Protection
回想一下早些时候我们引入了内核模式和用户模式的概念,我们简单地谈论了引入内核模式的好处和对系统的保护。在对待I/O设备上,我们也希望用户对I/O设备的访问和操作在系统内核的监督下进行,避免用户因不当指令导致系统或设备的故障(例如,启动一个I/O的后背隐藏能源)。同时,我们还希望操作系统可以帮我们检查该指令是否有效。
2.5.1 Direct Access
模式转换往往意味着开销。在这里,我们实际上用了性能为代价增加了系统的安全性。但有时候,我们想发挥系统的全部性能。比如说,显卡(graphic card)。在玩游戏时,为了获得全部的性能,我们想要游戏直接访问显卡的内存(direct access)。如果让每次访问(access)都经过内核,那带来的游戏体验将会很差。
因此,为了让用户获得显卡和处理器的全部性能,内核将会给予特定的游戏进程有关游戏显示相关的那一部分显卡内存的相关权限。这种情况下,应用进程访问这部分显卡内存将不需要经过内核的协助。少了内核中间商赚差价,性能收益自然就高了。
2.6 Kernel I/O Data Structure
对于操作系统内核而言,知道哪个设备和主机建立了连接、设备正在为哪个进程所使用和当前设备的状态信息是必须的。在后续学习的文件系统中,我们会了解到“万物皆文件”的理念。在实际的进程内存和内核内存中,都记录着一些文件描述符(file descriptor)。内核就是根据这些文件描述符来操作I/O设备的。

后续文件系统的学习中,我们会补充打开文件表是如何为设备的访问提供抄近道的机会。此外,经过了文件系统的封装,某些设备访问出错时就会直接返回错误码,将I/O硬件隔离开,提供了硬件的安全性。
2.7 I/O Scheduling and Performance
大多数的I/O操作都是异步的,这意味着I/O设备的请求可能在任何时间点到来。这些请求源自用户程序,操作系统需要及时将请求加入到设备的队列中,并对这些I/O请求进行调度。操作系统根据队列中的信息了解设备状态,并对这些I/O请求进行定位和调度。
在FCFS的I/O调度方式中。当线程想要使用设备时,它会先检查设备的状态。如果设备空闲,就将设备的状态设置为忙并立即提交请求;如果设备忙,则将阻塞线程并将线程加入到等待队列中。当设备使用完毕后,我们可以将队列中的线程唤醒(unblock),然后让其使用I/O。当没有线程使用设备时,就将设备的状态置为空闲。
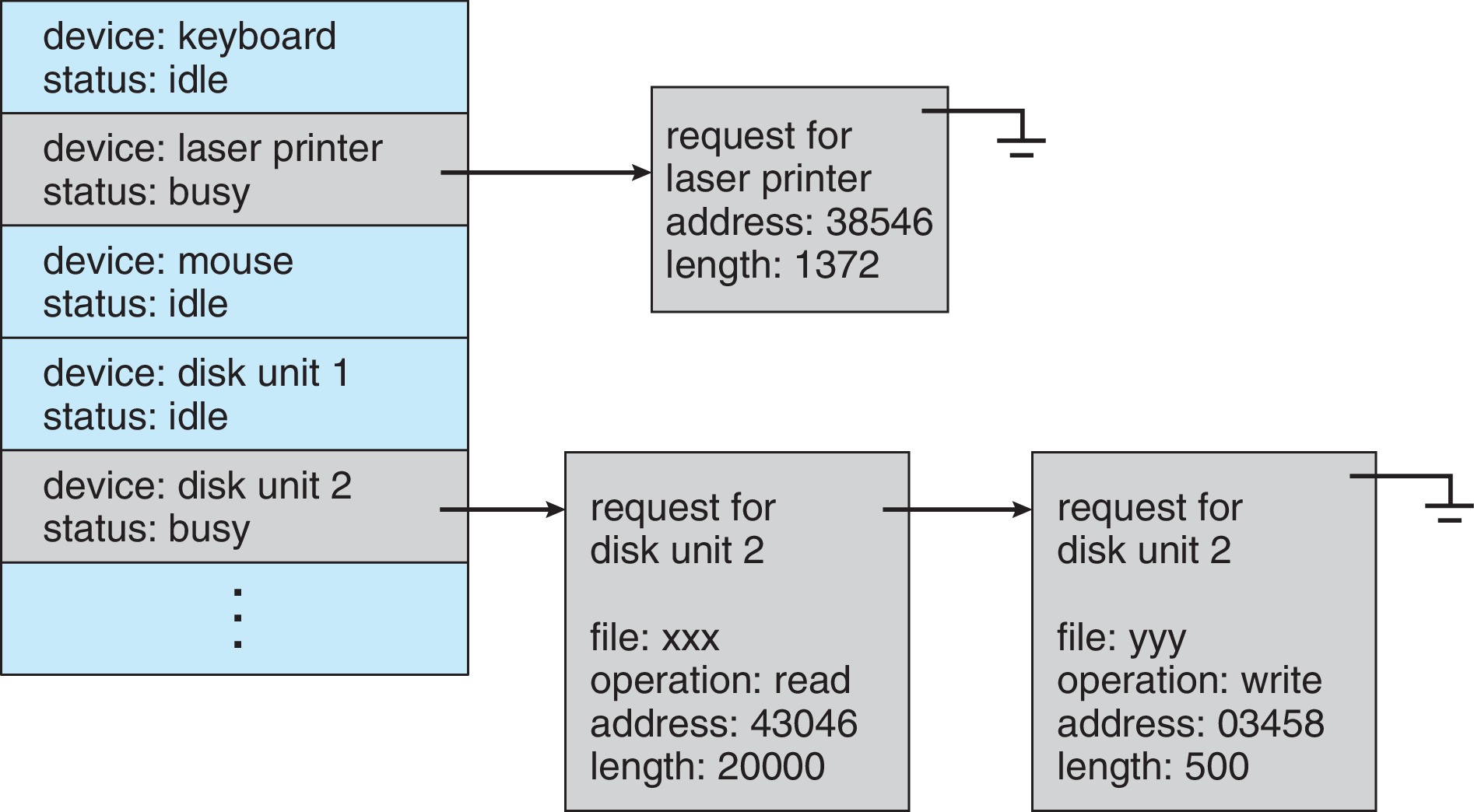
2.7.1 Fair but Inefficient
我们刚才谈论了FCFS的I/O调度方式。尽管这种方式非常公平,但未必是最高效的。CPU调度为我们提供了很多调度I/O的思路。例如,在CPU调度阶段中,我们学到了优先级,并将进程分为不同的等级。同样,在I/O调度上,我们也可以根据进程的优先级对I/O进行调度,让高优先级的进程优先使用I/O。
然而,I/O设备并不像进程那样可以通过CPU和RAM进行统一操作。对于I/O设备而言,非一致性访问时间(non-uniform access time)更为关键,因为I/O很慢嘛。对于闪存驱动器(flash drive),读和写的时间不因数据的物理位置不同而变化,但对于其他类型的设备,访问时间可能会有所不同。然而,对于类似于硬盘这样的I/O设备而言,物理结构和操作方式导致了访问时间的变化。
2.8 The STREAMS Structure

2.9 Life Cycle of a I/O Request

2.9.1 Intercomputer Communications using I/O
在使用telnet或SSH时,打一个字母到远程主机会发生以下的中断:
- 本地的键盘中断
- 本地的网络请求中断
- 远程的网络达到中断
- 编辑器进程打印字母并更新屏幕
- 远程的网络请求中断
- 本地的网络到达中断
为了显示一个字符,我们可真是做了不少。

如何减少中断呢?我们有很多鬼点子,比如将进程直接放到核心态去运行,这就不会产生任何中断了,但是太危险,不可取。第二种方案就是找一种功能特化的硬件来专门处理,像TLB那样,但是增加费用的同时还提升了学习成本,也不可取。那我们可以像之前学习buffer那样等输入一个块的数据后在将数据发送到远程服务器上去么?这种情形下肯定不可以了。
而这种情况下使用DMA就能算得上是一个不错的选择了,DMA控制器负责将数据从网络适配器传输到系统内存,而不需要CPU的干预。这样,系统可以减少CPU处理I/O请求的次数,减少了两次中断的发生。还不错。
2.10 Security in I/O Devices
一些I/O设备可能会为操作系统带来一些安全隐患。这是因为设备的驱动抽象是运行在操作系统内核中的,操作系统非常信任这些drivers,这就为安全问题埋下了隐患。攻击者可能通过利用系统中的漏洞、配置错误或弱访问控制,获得比其原本权限更高的访问权限。(Privilege escalation)